What Is a Large Language Model, Without the Hype


Table of Contents
A large language model is a system that has been trained to do one deceptively simple thing: predict the next word. Show it a stretch of text, and it guesses what most likely comes next, then it guesses again, and again, one piece at a time, until it has produced a whole answer. That is the entire mechanism underneath ChatGPT, Claude, Gemini, and every other tool you have heard called an LLM. Everything impressive they do is built on next-word prediction at an enormous scale.
That sentence usually gets one of two reactions. Either "that cannot possibly be all it is," or "if that is all it is, why does everyone act like it is magic?" Both are fair, and the honest answer sits between them. The mechanism really is that simple. What is surprising, and what genuinely caught even the researchers who built these systems off guard, is how much capability falls out of doing that one simple thing at a massive enough scale. Let me explain it properly, in plain language, so the tool stops being a black box.
The core idea: a very, very good autocomplete
You already use a tiny version of this every day. Your phone's keyboard suggests the next word as you type. It looks at what you have written and offers its best guess. A large language model is that same idea, scaled up by a factor so large it stops behaving like autocomplete and starts behaving like something that can write, summarise, translate, and answer questions.
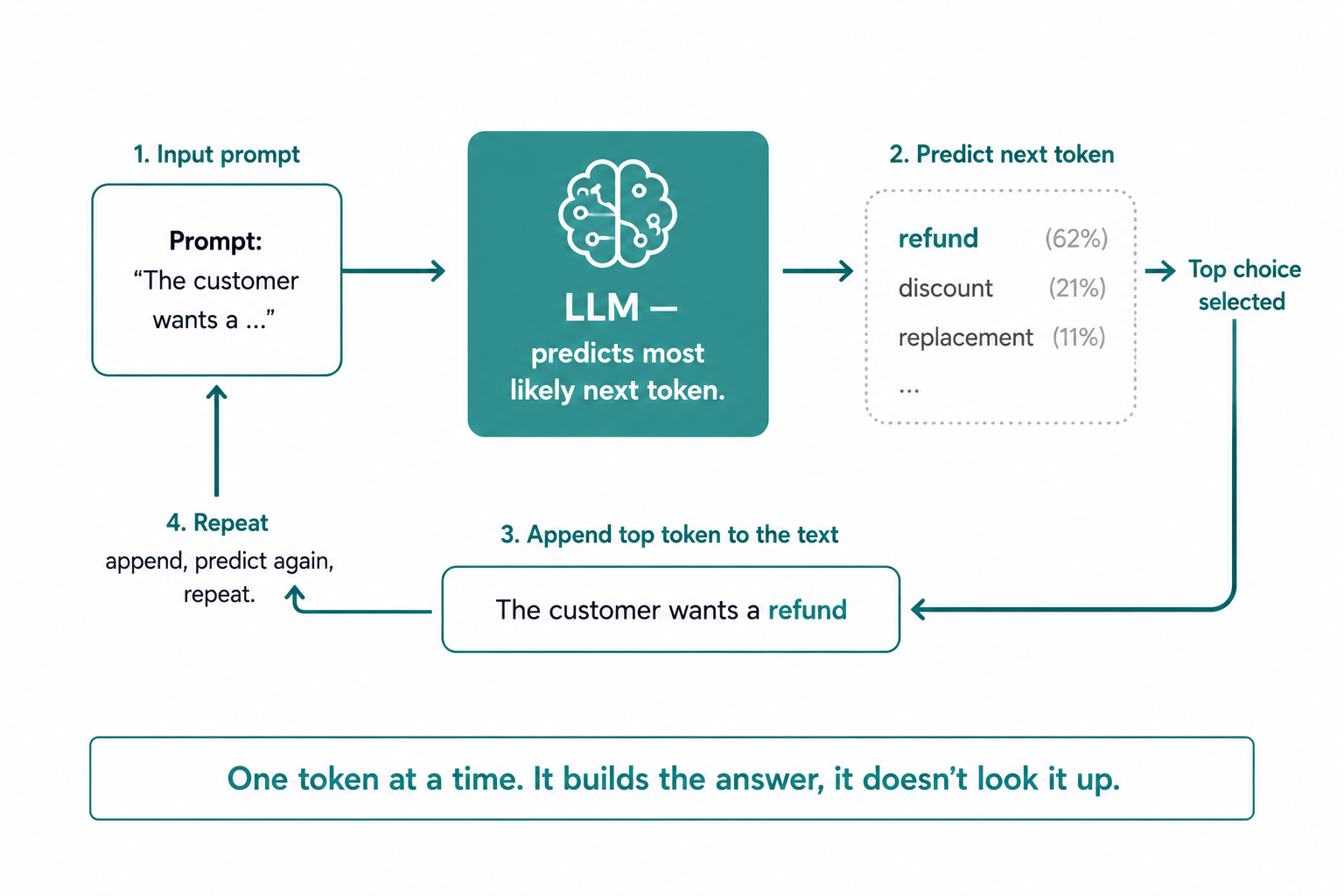
Here is the mechanism in full. The model is shown a piece of text, called the prompt. It breaks that text into small units called tokens, which are roughly words or word-fragments. Then, based on everything it learned in training, it calculates the most likely next token and produces it. Then it adds that token to the text and repeats the whole process to produce the next one. It does this over and over, one token at a time, until the response is complete. It does not know the final answer in advance and work backward. It builds the answer one best-guess step at a time, the way you might if you could only ever see the sentence so far.
The critical thing to understand is that the model is not looking anything up. It has no database of answers inside it. It is making a statistical prediction at every single step, based on patterns it absorbed during training. That one fact explains both why LLMs are so flexible and why they sometimes confidently state things that are wrong, which I will come back to.
Why "large" matters: scale is the whole trick
The word "large" is doing a lot of work in the name, and it points at the part that actually matters. These models are trained on staggering amounts of text, hundreds of billions to trillions of tokens, drawn from books, websites, code repositories, encyclopaedias, and more. And they contain billions, sometimes trillions, of internal settings called parameters: the dials, tuned during training, that encode all the patterns the model picked up.
Here is why that scale is not just a bigger version of your phone keyboard. When a model learns to predict the next token across a large enough slice of human writing, it is not only learning that "thank" is often followed by "you." To get good at the prediction, it ends up absorbing grammar, facts, writing styles, the structure of arguments, code patterns, and the relationships between ideas, because all of those things are needed to predict text well. Nobody programmed those abilities in. They emerged as a side effect of getting very good at next-token prediction at scale. This relationship, where more data and more parameters reliably produce more capability, is well established enough that it has a name: the scaling law. The simplicity of the goal and the richness of what emerges from pursuing it at scale is the genuinely remarkable part, and it is the thing worth being impressed by, rather than the marketing around it.
The engine underneath that makes this possible is an architecture called the transformer, introduced in 2017. Its key trick is that it can weigh how every word in a passage relates to every other word, all at once, rather than reading strictly left to right. That is what lets a model keep track of context across a long passage. You do not need to know how a transformer works internally to use an LLM well, any more than you need to understand an engine to drive, but it is the breakthrough that made all of this possible, so it is worth knowing the name.
How a raw model becomes a helpful assistant
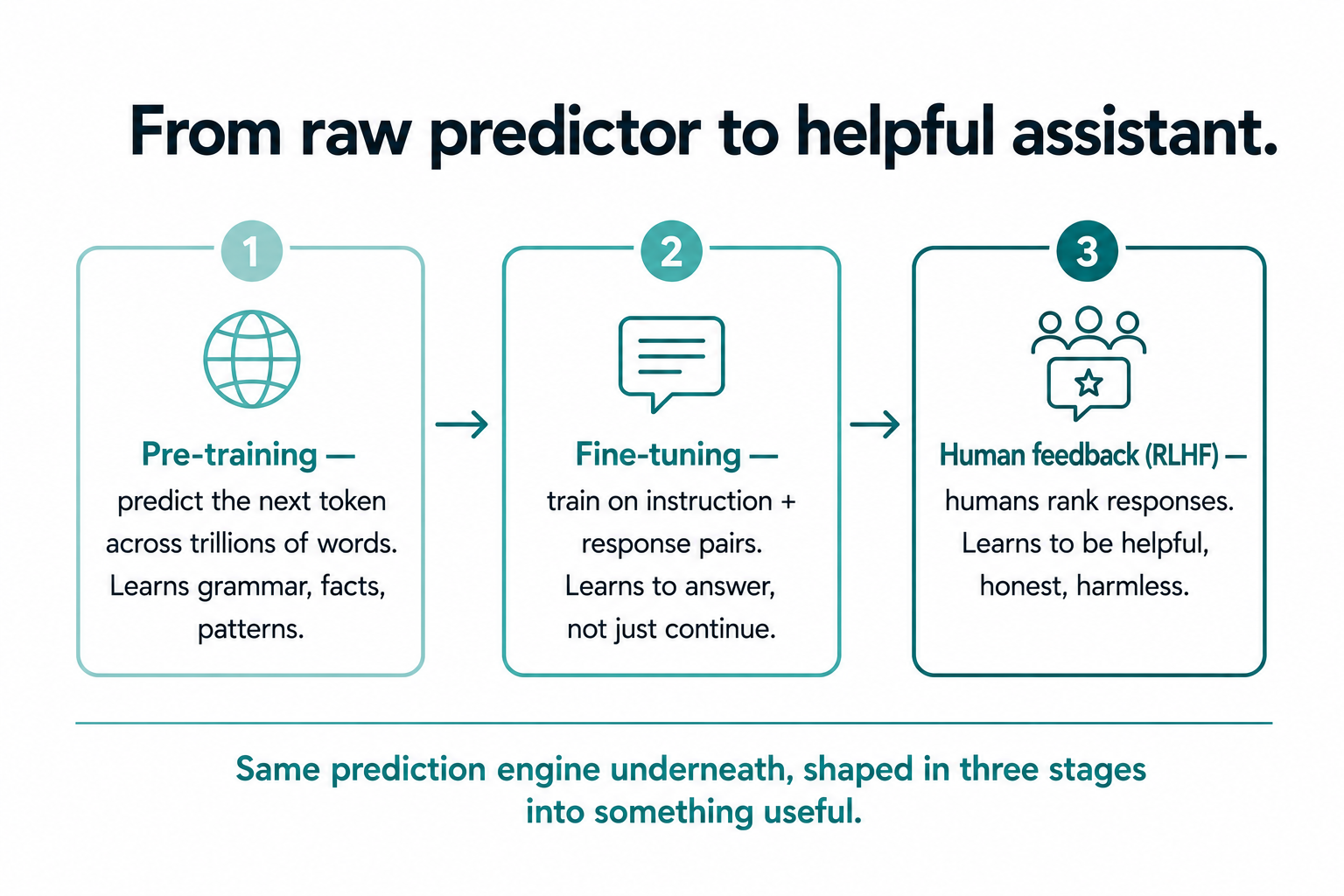
A freshly trained model is powerful but raw. It predicts text, which is not the same as answering your question. Left to its own devices, a purely pre-trained model asked "what is the capital of France?" might just as plausibly continue with more questions in the same style, because that is also a likely way for that text to continue. Turning that raw predictor into something useful takes two further steps, and they are worth knowing because they explain why these tools feel the way they do.
First, fine-tuning on instructions. The model is trained further on many examples of instructions paired with good responses, which teaches it that when it sees a question, the desired continuation is an answer, not more questions. Second, learning from human feedback, often abbreviated RLHF. Humans rank different responses, and the model is nudged toward the kinds of answers people rate as helpful, honest, and harmless. This is the stage that gives a model its helpful, conversational manner, and it is a big part of why one model can feel more pleasant or more careful than another even when the underlying prediction engine is similar.
So the full picture is: a transformer learns language by predicting the next token across a vast amount of text, then gets fine-tuned and shaped by human feedback into something that responds the way you actually want. Three stages, one underlying mechanism.
What this means in practice: why it hallucinates
Understanding the mechanism pays off the moment something goes wrong, because it explains the single most important limitation of these tools. Since an LLM generates answers by predicting plausible text rather than looking up facts, it can produce something that reads perfectly and is completely false. It is not lying, and it is not broken. It is doing exactly what it was built to do: producing the most likely-sounding continuation. When the true answer and the plausible-sounding answer happen to diverge, you can get a confident, fluent, wrong response. This is called hallucination, and it is a direct consequence of the mechanism, not a bug that will be fully patched away. (It is a big enough topic to deserve its own explanation, but the root cause is right here in how the model works.)
This is also why techniques exist to give models access to real, current information rather than relying only on what they absorbed in training, and why the better systems are built to check their outputs against real sources. Knowing that the model is a predictor, not a knower, is the single most useful thing you can hold in your head when deciding how much to trust any given answer.
So that is a large language model, without the hype. A system trained to predict the next token, scaled up until grammar, facts, and reasoning-like structure emerge from the prediction, then shaped by fine-tuning and human feedback into a helpful assistant. Not magic, and not a lookup table. A remarkably capable pattern-prediction engine, and one you will use far more effectively once you understand that is what it is. If you want to see where this fits into the bigger picture, an LLM is the reasoning core inside an AI agent, which adds memory, planning, and tools on top of it.
A few common questions
What is a large language model in simple terms? A system trained to predict the next word (token) in a sequence. Given some text, it repeatedly guesses the most likely next piece, one at a time, until it produces a full response. At enough scale, this simple mechanism can summarise, translate, answer questions, write code, and hold a conversation.
How does an LLM actually work? It breaks your prompt into tokens, then predicts the most likely next token based on patterns learned during training, appends it, and repeats. It is not looking answers up in a database; it is making a statistical prediction at every step. The transformer architecture is what lets it weigh how all the words relate to each other.
Why do large language models make things up? Because they generate plausible text rather than retrieving facts. When the most likely-sounding continuation happens not to match the truth, you get a confident but wrong answer, known as a hallucination. It is a direct consequence of how the model works, not a simple bug.
What does "large" mean in large language model? Two things: the model is trained on an enormous amount of text (hundreds of billions to trillions of tokens) and contains a huge number of parameters (the internal settings that encode learned patterns). Scale is what turns simple next-word prediction into genuine capability.
You should also read:
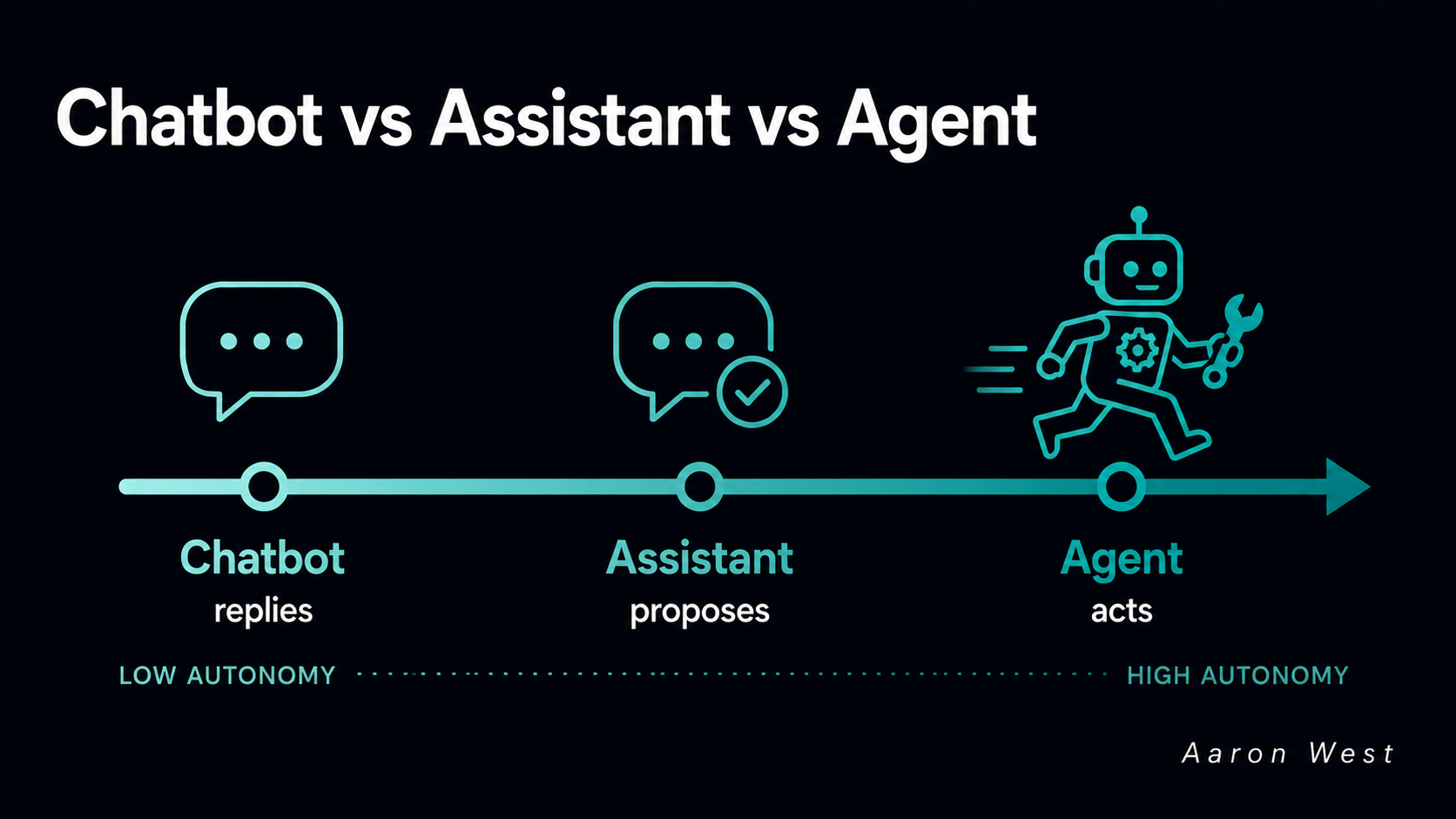
What Is an AI Agent? The Difference Between a Chatbot, an Assistant, and an Agent
An AI agent is a system that takes a goal, breaks it into steps, uses tools to carry those steps out, and decides on its own what to do next based on what just happened. That last part is the whole difference. A chatbot answers…
Continue reading...