How I Think About Automation in E-Commerce


Table of Contents
- What automation in e-commerce actually is
- The classification that decides everything
- You cannot automate what you haven't documented
- What to automate, and the five things never to
- Event-driven or scheduled: the architecture choice nobody explains
- The error notification is the actual workflow
- The 2026 question: should agents run it?
- What automation is actually for
- A few common questions
The most expensive automation mistake I see isn't a broken workflow. It's a flawless workflow automating a task that should never have existed in the first place.
I've watched smart people spend a weekend building something genuinely impressive. A form that triggers an email, creates a folder, updates a spreadsheet, pings a Slack channel, all wired together perfectly, to automate a process nobody had ever questioned. The automation worked. The process underneath it was the problem. They'd just made a bad process run faster and harder to change.
So before I touch a single tool, I ask one question about the work in front of me: does this task need a human brain, or does it just currently have one? Almost everything I know about automation comes from getting that question right. Here's the full framework.
What automation in e-commerce actually is
Automation is the removal of a category of work from human hands so that human attention can move to the work that actually needs it. That's the definition I operate from. Notice what it doesn't say: it doesn't say "doing more, faster." Speed is a side effect. The point is reallocation. You take the repetitive, rules-based work off your team's plate so they can spend their hours on judgment, relationships, and decisions a machine can't make.
This matters because most automation advice gets the goal wrong. It treats automation as a productivity hack, a way to squeeze more output from the same people. That framing leads you straight to the mistake I opened with: automating whatever looks busy, instead of asking what should exist at all.
The teams that get real value from automation don't start with tools. They start with a classification.
The classification that decides everything
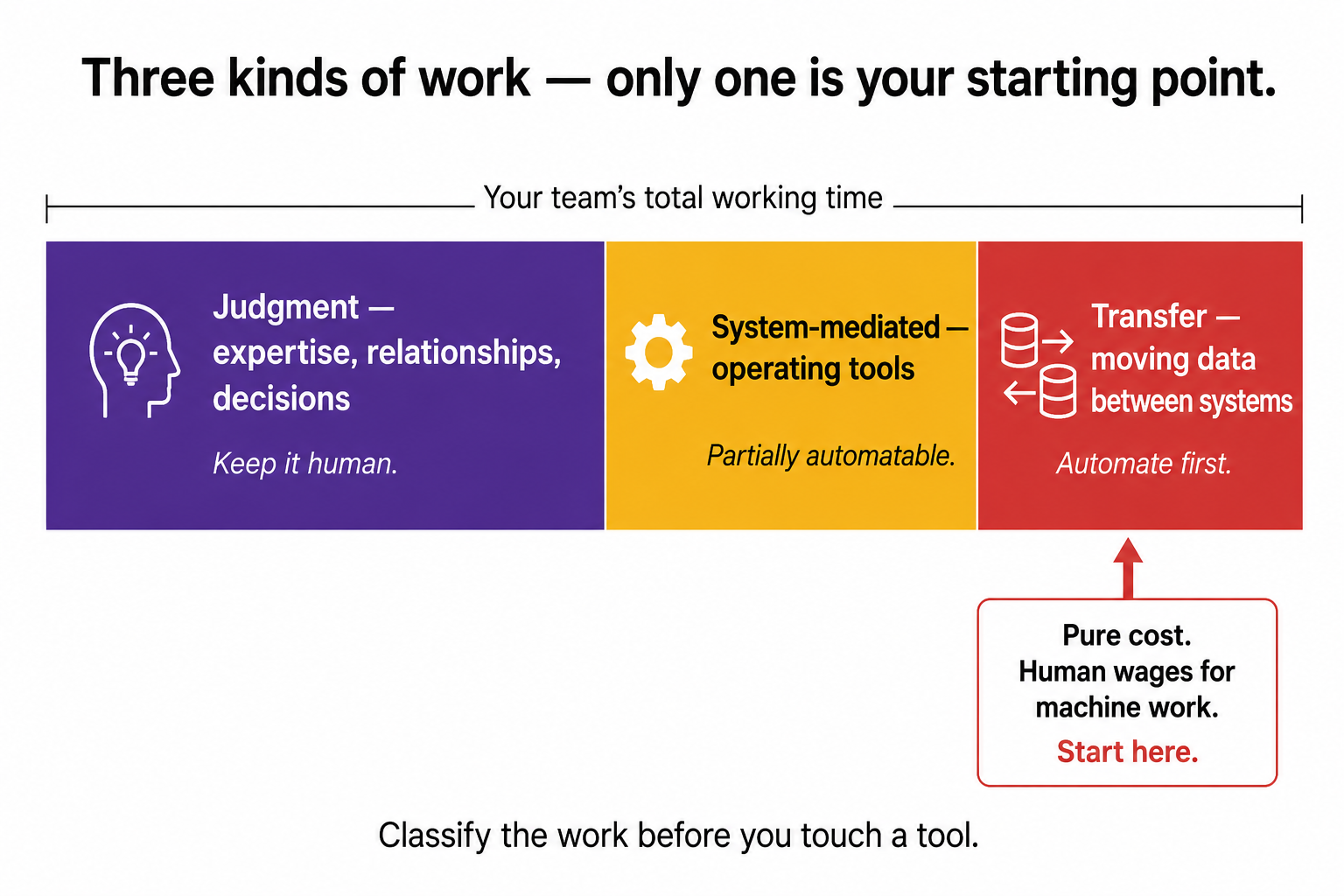
Every task your team does falls into one of three categories. Getting this right is 80% of the work.
Judgment tasks. The person's expertise, creativity, or relationships are genuinely required. Negotiating with a supplier. Deciding which campaign to kill. Handling a furious customer whose order vanished on their wedding day. These cannot be automated, and trying to automate them produces something worse than the manual version.
System-mediated tasks. The person is operating a tool to get something done, like building a report in an analytics platform or configuring a campaign. These are partially automatable. Often the data-gathering can be automated while the interpretation stays human.
Transfer tasks. The person is moving information from one place to another. Exporting a report and reformatting it. Copying order data between two systems that don't talk. Re-entering the same figures into a spreadsheet every Monday. No judgment is involved. The person is acting as a very expensive, error-prone API between two systems.
Transfer tasks are where you start. Always. They're pure cost. You're paying a human wage for machine work, and humans introduce errors that machines don't. Manual data entry carries an error rate of roughly one percent per field, which sounds small until you multiply it across a twenty-field order record and realise you're shipping a mistake every few orders.
The discipline is refusing to automate anything until you've classified it. The weekend-warrior mistake is automating a transfer task that turned out to be propping up a process that should have been deleted.
You cannot automate what you haven't documented
Once you've found a transfer task worth automating, the instinct is to open Make or Zapier and start building. Resist it. The step everyone skips is writing down what the process actually does. Every step, every system, every decision point, and crucially every failure mode.
This isn't bureaucracy. It's the difference between automating a process and automating your assumptions about a process. When you map a workflow in detail, you almost always discover steps that exist for reasons nobody remembers, exceptions the original person handled silently, and edge cases that would have broken your automation the first week. Mapping the current workflow before automating it is the single most consistent piece of advice across every serious practitioner guide, and it's consistently the step people are most tempted to skip.
My method is unglamorous: two weeks of time-tracking in fifteen-minute blocks across the team, then classify every logged task, then map the transfer tasks step by step before building anything. The two weeks of tracking captures the weekly cycle, the Monday reports and the Friday reconciliations, that a one-day snapshot misses. I wrote up the full version of this in how to run an automation audit on your own team in two weeks, but the principle is simple: measure first, build second.
There's a fast test I apply to every candidate task before committing: if the person who does this called in sick tomorrow, what would actually break? If the honest answer is "nothing, it'd just be a bit late," that task is a candidate for elimination, not automation. If the answer is "something important," now you know what you're protecting, and you can automate it properly.
What to automate, and the five things never to
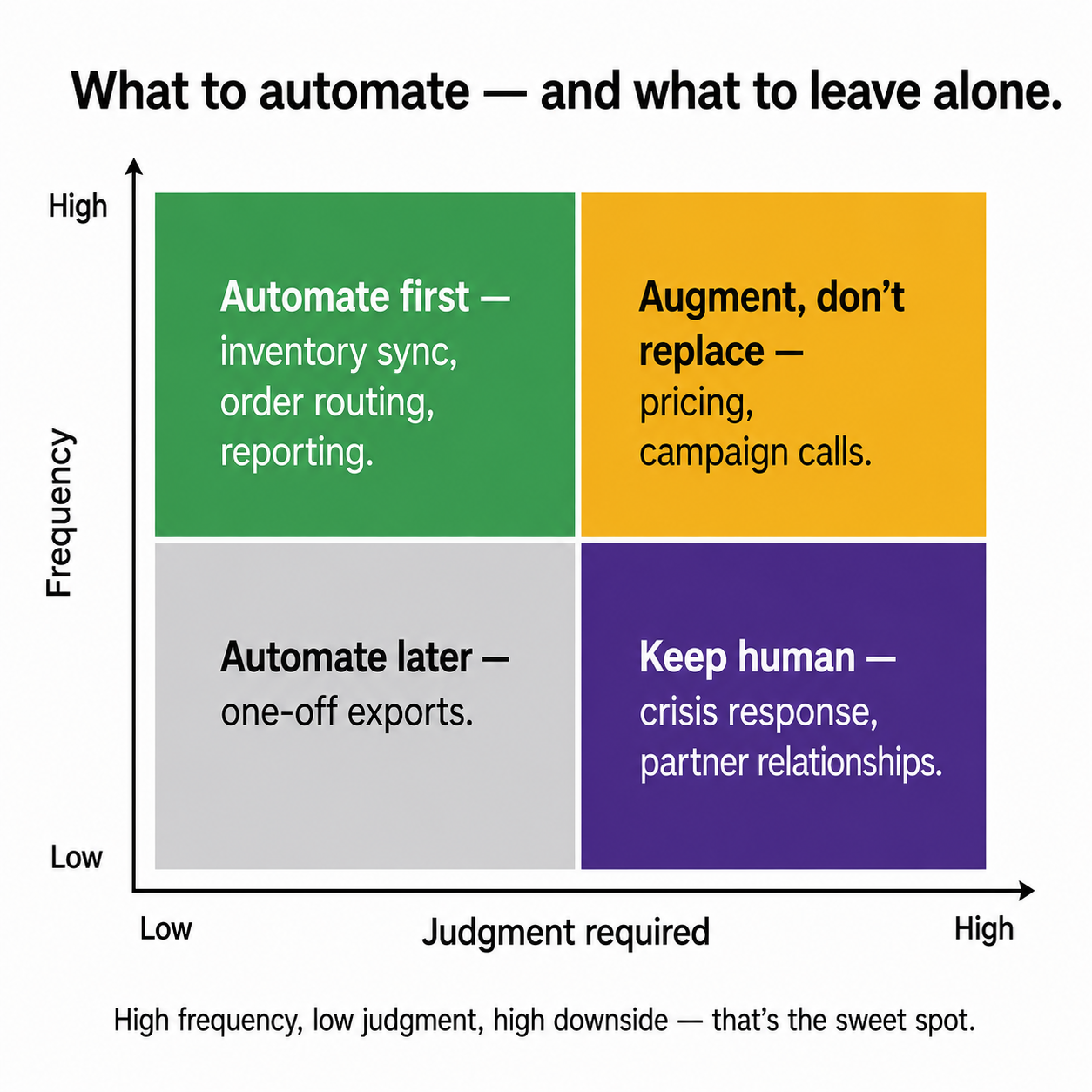
The highest-value automation candidates share three properties: they happen often (daily or weekly), they take meaningful time, and they cause real damage when they go wrong. High frequency, low judgment, high downside. That's the sweet spot. Inventory synchronisation and order routing are the classic starting points for exactly this reason. They run constantly, they're pure rules, and a mistake costs you an oversold order and an angry customer.
But the more useful list is the one nobody publishes: what you should never automate, no matter how tempting.
Don't automate the irreversible without a human gate. A refund that fires before the returned item is confirmed received isn't efficiency, it's a fraud vector. Don't automate relationship moments, like the personal note to a top affiliate partner or the apology to a customer you let down. Don't automate crisis response, where every situation is genuinely novel. Don't automate a decision that requires weighing things the system can't see. And don't automate anything you haven't documented, because you'll just be encoding a process you don't understand.
The pattern underneath all five: anything where being wrong is expensive and the situation varies stays human, or stays human-gated. This is why I treat the post-purchase moment as automatable but the returns triage refund step as something that always needs a confirmation gate. Same workflow, different risk profile, different rule.
Event-driven or scheduled: the architecture choice nobody explains
Once you know what to automate, there's a design decision that determines whether your automation actually solves the problem: does it run on a schedule, or does it react to an event?
A scheduled automation runs at a fixed time. Every morning at 8am, pull the sales figures. An event-driven automation runs the moment something happens. A customer places an order, so the inventory count updates instantly. The distinction sounds technical, but it's really a question about whether timing matters to the outcome.
If a customer buys your last unit and your stock count only updates in tonight's scheduled sync, you'll oversell it this afternoon. That problem requires an event-driven trigger. The order event fires the update in real time. But a monthly partner report doesn't need real-time anything; a schedule is simpler, cheaper, and perfectly adequate. I go deeper on this in event-driven vs scheduled automation explained, but the rule of thumb is: if the cost of being slightly out of date is real, go event-driven. If it isn't, schedule it and keep it simple.
Getting this wrong is subtle because the automation still "works." It just works at the wrong moment. That's the kind of failure that's invisible until it costs you a sale.
The error notification is the actual workflow
Here's the principle I'd tattoo on anyone building their first automation: a silent failure is worse than no automation at all.
When a task is manual, its failure is visible. The report doesn't get sent, someone notices, someone fixes it. When you automate that task and it breaks quietly, maybe an expired API token, a changed field name, or a service outage, nobody notices, because the whole point was that nobody had to think about it anymore. You discover the failure weeks later, when the damage has compounded. With no automation, at least the gap is obvious. With broken-and-silent automation, you have false confidence.
So every workflow I build has a monitoring step that fires an alert, a Slack message or an email, the moment something fails. It costs maybe thirty extra minutes of build time. It has saved me from discovering broken automations months after they failed more times than I can count. I made this its own piece because it matters that much: the error notification is the workflow.
If you build only one habit from this entire framework, build this one. The automation that tells you when it's broken is worth more than the automation that's slightly more elegant.
The 2026 question: should agents run it?
I can't write about automation in 2026 without addressing the shift everyone's talking about: the move from rigid rule-based automation (the "if this, then that" flows) to agentic AI, where an LLM-driven agent reasons through a situation instead of following a fixed script.
My honest take, as someone who builds this for a living: agents are a genuine capability upgrade for one specific thing: the messy middle, where the input is unstructured and the path varies. A rigid workflow can't handle "the supplier sent a weird email about a partial shipment delay." An agent can read it, understand it, and route it. That's real, and it's new.
But agents come with a cost that the hype skips: they're non-deterministic. A rule-based flow does exactly the same thing every time, which is exactly what you want for order processing and inventory sync. An agent might do something slightly different each time, which is exactly what you don't want for anything financial or irreversible. They also cost more to run and are harder to monitor.
So I don't treat it as agents-versus-automation. I treat it as a division of labour. Deterministic, high-stakes, repetitive work stays as rigid automation, predictable by design. The unstructured, judgment-adjacent messy middle is where an agent earns its place, and even then, anything sensitive keeps a human in the loop. Human-in-the-loop for high-value or irreversible actions isn't a limitation of current agents; it's just good design, and it's becoming standard practice for a reason.
The new tools are exciting. The discipline that decides where to use them hasn't changed at all.
What automation is actually for
The teams I've seen get the most from automation are not the ones that automated to cut headcount. They're the ones that automated to redirect the same people to better work. The analyst who stopped pulling reports started doing actual analysis. The ops person who stopped triaging returns by hand started fixing the supplier relationships that were causing the returns.
That's the part that never shows up in a time-saved number. You can measure the hours a workflow gives back. You can't as easily measure what those hours get spent on instead, and that second thing is where the real return lives. It's also why I'm sceptical of automation pitched purely as a cost-cutting exercise. Cutting cost is the small win. Moving your best people off machine work and onto the decisions only they can make is the big one.
Automation isn't about doing more things. It's about doing fewer things manually so you can do the important things well.
That's the whole philosophy. Everything else (the tools, the triggers, the architecture) is just implementation.
A few common questions
What should an e-commerce business automate first? The highest-value first target is almost always inventory synchronisation or order routing: high frequency, no judgment required, and expensive when it goes wrong. Start with the task that costs the most when it breaks, not the one that's most annoying.
What should never be automated? Anything irreversible without a human gate, anything relationship-driven, crisis response, decisions requiring information the system can't see, and any process you haven't fully documented.
Do I need AI agents to automate my store? No. Most high-value e-commerce automation is deterministic rule-based work like inventory, routing, reporting, and follow-ups, and should stay that way. Agents earn their place on unstructured, varying tasks, with a human in the loop for anything sensitive.
How do I know what to automate? Track your team's work for two weeks, classify every task as judgment, system-mediated, or transfer, and start with the transfer tasks. Document each one fully before you build.
You should also read:
The Multilingual Chatbot Problem Nobody Warns You About
Here is the trap almost every multilingual chatbot project falls into: treating "support more languages" as a translation task. You build the bot in one language, get it working, then hand the whole thing to a translation step and assume you are done. You are…
Continue reading...
Everything I Know About Building Chatbots That Actually Work
The hard part of building a chatbot was never the technology. I learned this in 2019, building a natural-language chatbot from scratch for a large hotel group, across dozens of locations and several languages, back when "conversational AI" was a research term and not a…
Continue reading...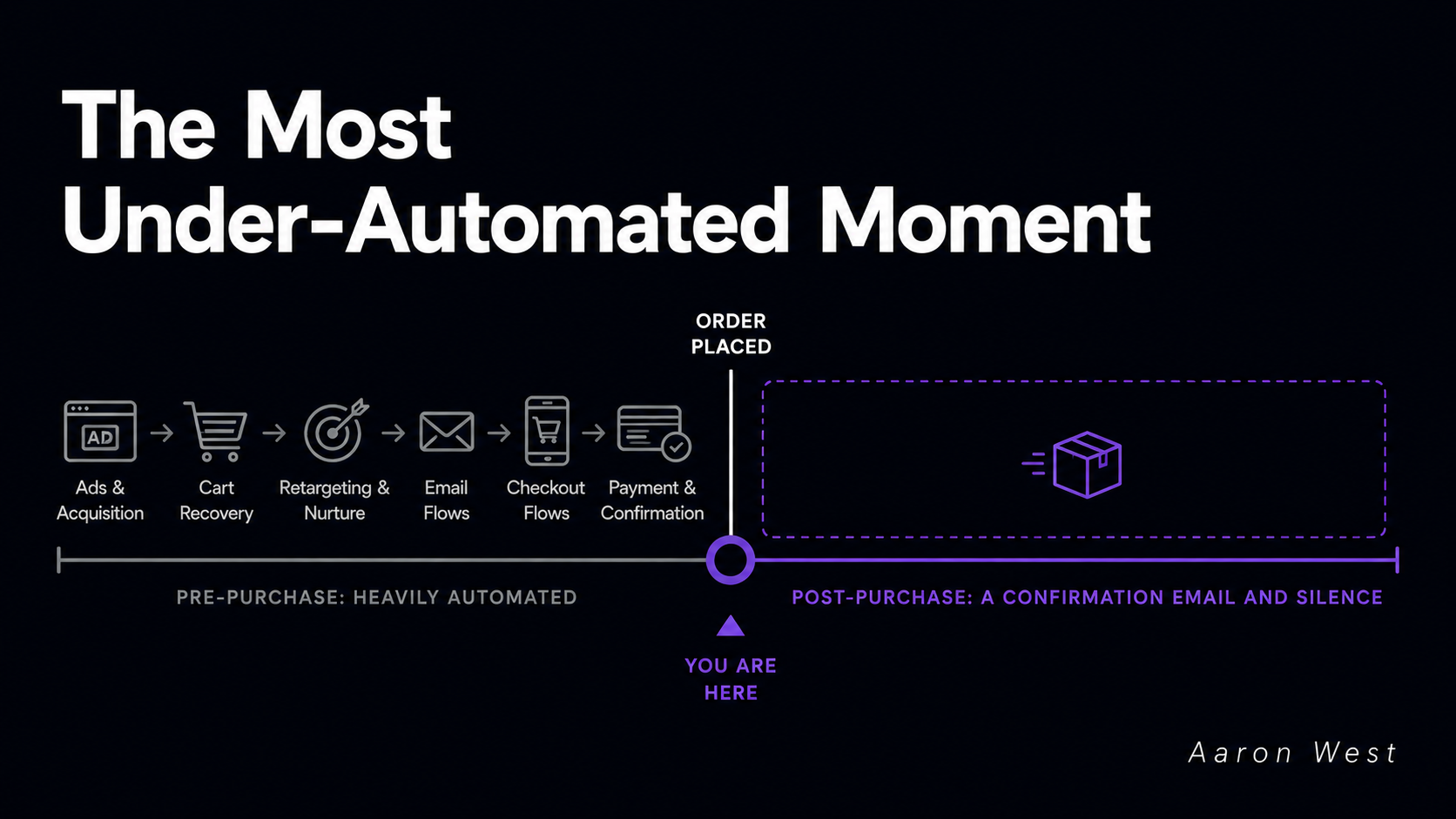
Post-Purchase Is the Most Under-Automated Moment in E-Commerce
Almost every store pours its automation budget into the moment before the sale and abandons the customer the moment after it. Cart recovery, retargeting, checkout nudges, all heavily automated. Then the order goes through, and the experience falls off a cliff into a generic "thanks…
Continue reading...