The Hidden Cost of Manual Operations


Table of Contents
Ask most e-commerce teams what their operations cost, and they will point you to the obvious line items. Software subscriptions. Fulfilment fees. Headcount. What almost nobody can tell you is the cost of the work itself, the hours that disappear every week into copying data between systems, reformatting reports, and re-entering numbers a machine could have moved. That cost is real, it is large, and it hides because it never appears as its own line on any budget.
Here is a number to anchor it. A 2025 survey by Parseur and QuestionPro put the cost of manual data entry at an average of $28,500 per employee per year. That is not the cost of the employee. That is the slice of one employee's salary spent on work that did not need a human at all. Multiply it across a team and you are looking at a six-figure cost nobody decided to spend.
This is the cost I go looking for first whenever I assess an operation. Let me show you where it hides and how to actually measure it, because "we waste time on manual work" is a feeling, and you cannot fix a feeling. You fix a number.
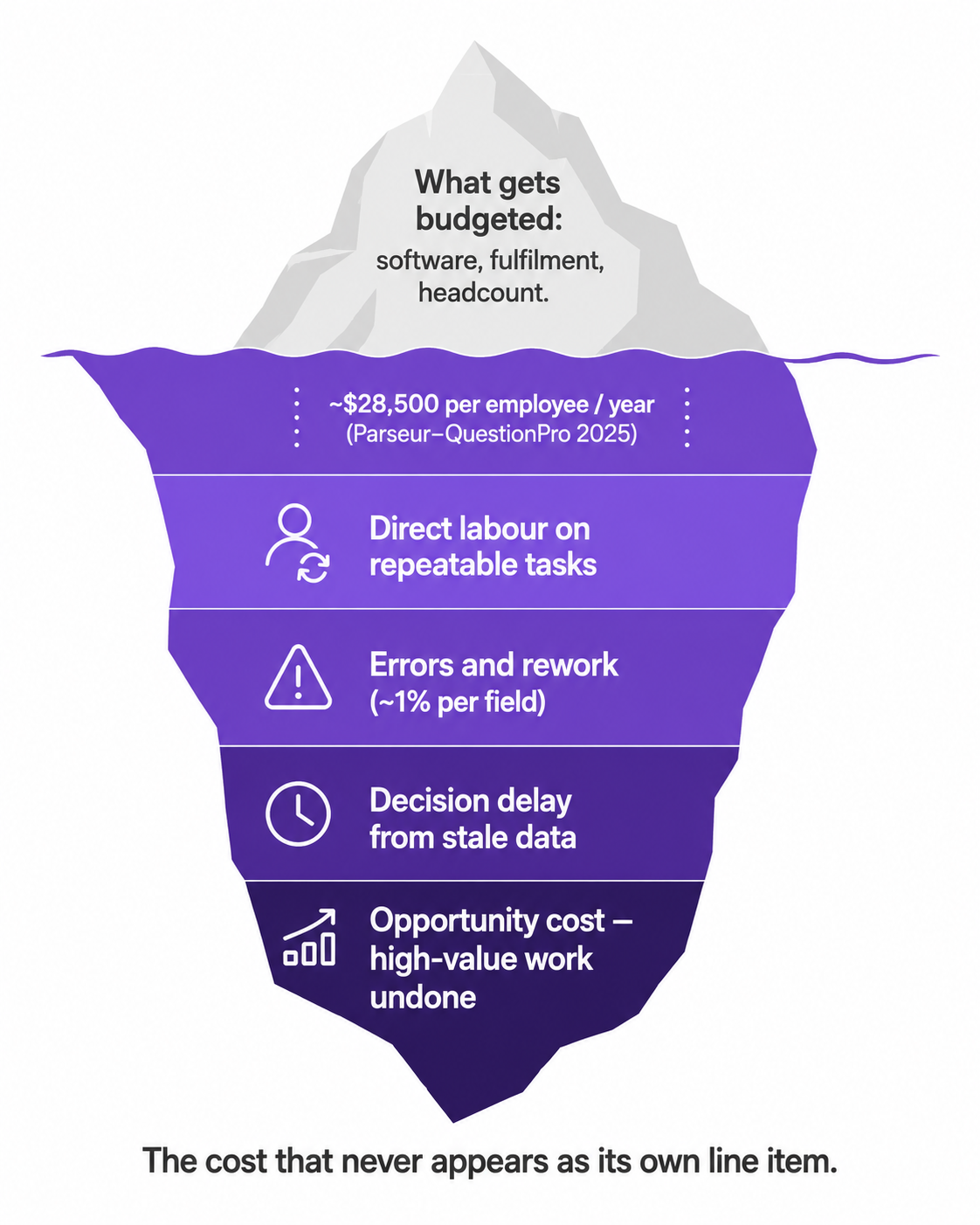
The four places the cost hides
Manual operation cost is hard to see because it is scattered across four different places, and no single one of them looks alarming on its own.
The first is direct labour. Someone spends thirty minutes every morning pulling a report. That is two and a half hours a week, ten a month, around 120 a year. One task. At a typical loaded cost for a knowledge worker, that single habit runs into the thousands annually, and most teams have dozens of these habits running at once. None of them feels expensive in the moment. Together they are the biggest cost in the building that nobody has counted.
The second is errors. Manual data entry has a well-documented error rate of around one percent per field, a figure that turns up consistently across decades of data-quality research. One percent sounds harmless until you do the multiplication. Across a twenty-field order record, that is roughly a one-in-five chance of an error somewhere in every record. In e-commerce those errors are not abstract. They are wrong shipping addresses, mispriced items, orders entered against the wrong SKU. Each one costs far more to fix than it would have cost to prevent, because by the time you catch it, a customer is already involved.
The third is decision delay. When a report has to be assembled by hand before anyone can act on it, every decision waits for the assembly. Stale data is its own tax. You promote a product that is actually out of stock. You reorder against last month's sales pattern. You price against a competitor snapshot that is three weeks old. The decision was not wrong because the person was wrong. It was wrong because the data was late, and the data was late because moving it was manual.
The fourth is the one that matters most and shows up least: opportunity cost. Every hour your best people spend moving data is an hour they are not spending on the work only they can do. You are not just paying for a low-value task to get done. You are paying for a high-value task to go undone. That cost never appears anywhere, because the thing that did not happen leaves no trace.
Why it stays hidden
If this cost is so large, why does it survive? Because it is camouflaged by useful work.
The person pulling the morning report is not idle. They are doing something that looks like the job, often alongside genuinely valuable work, so the waste blends in. Nobody ever sat down and decided to spend $28,500 a year on copy-paste. It accumulated, one reasonable-seeming habit at a time, until it became simply "how we do things." That is the trap. Manual cost does not arrive as a decision you can question. It arrives as a routine you stop noticing.
The only way to see it clearly is to measure it deliberately. Which brings me to the part that actually matters.
How to measure it: the two-week audit
You cannot manage this cost by intuition, and you certainly cannot fix it by asking people "how much time do you waste?" because they genuinely do not know. The honest answer is always lower than the real one. You have to measure.
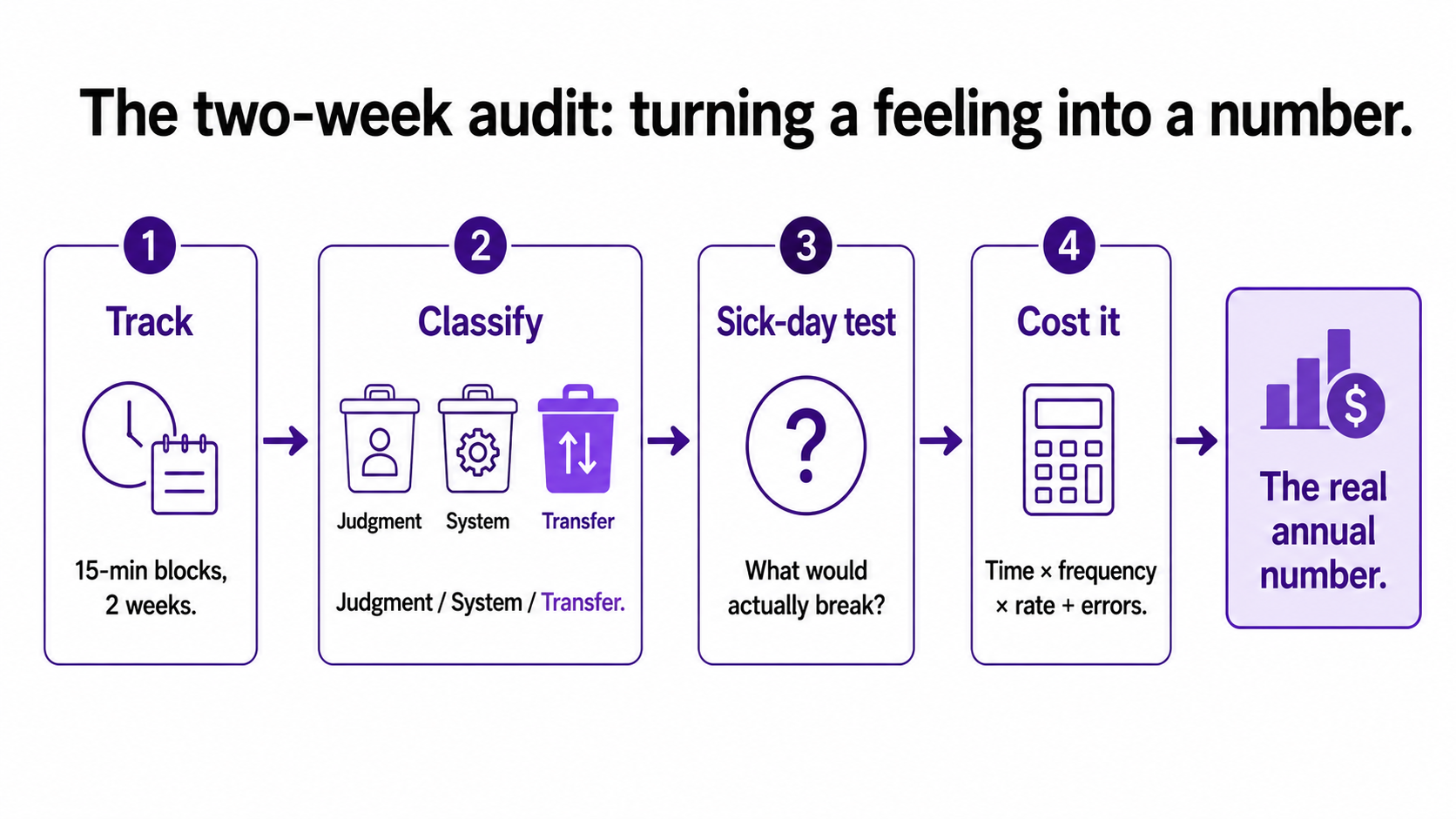
The method I use is unglamorous and it works. It has four steps.
Track for two weeks. Ask everyone to log what they actually do, in fifteen-minute blocks. Not what they think they do, what they actually do. Two weeks rather than one, because it catches the weekly rhythm, the Monday reports and the Friday reconciliations that a single week might land on either side of.
Classify every logged task into one of three kinds. Judgment work, where a person's expertise or relationships are genuinely required. System work, where someone is operating a tool to produce something. And transfer work, where someone is simply moving information from one place to another with no judgment involved. That third category, the transfer tasks, is where the hidden cost lives almost entirely.
Apply the sick-day test. For each transfer task, ask: if the person who does this were off sick tomorrow, what would actually break? If the honest answer is "nothing, it would just be a bit late," you have found not just an automation candidate but possibly a task that should not exist at all.
Cost it. For each automatable task, multiply the time per occurrence by how often it happens by the loaded hourly cost. Add a conservative estimate for the errors it produces. Annualise it. Now the feeling is a number, and the number is almost always bigger than anyone on the team guessed.
I wrote a full step-by-step version of this in how to run an automation audit on your own team in two weeks. The short version is the one that matters here: measure first, in fifteen-minute blocks, for two weeks. Everything else follows from having the real number.
What the numbers tend to reveal
When teams actually run this, the pattern is remarkably consistent. Somewhere between fifteen and twenty-five percent of logged time turns out to be transfer work, pure data movement with no judgment in it. A handful of recurring workflows, usually five to eight, account for the bulk of it. And the tasks themselves are nearly always the same suspects: inventory reconciliation, sales reporting, moving order data between systems that do not talk to each other, and routing returns by hand.
The dollar figure that falls out of this for a mid-sized team usually lands somewhere in the tens of thousands per year, before you have even counted the error costs or the opportunity cost. That is the moment the conversation changes. It stops being "should we bother automating this?" and becomes "why have we been paying for this by hand for so long?"
The point is not cheaper. It is better.
Here is where I part ways with most of the writing on this topic, which frames the whole thing as cost-cutting. Cutting cost is the small win. If all you do is automate the report-pulling and pocket the saved hours as a smaller wage bill, you have missed the actual prize.
The teams that get real value do something different. They take the hours back and redirect them. The analyst who stopped assembling reports starts interpreting them. The operations person who stopped routing returns by hand starts fixing the supplier problems that were causing the returns in the first place. The cost you remove is measurable. The value you unlock by moving good people onto work that needs a brain is much larger, and it never shows up in the time-saved number.
That is the real hidden cost of manual operations. Not the money, though the money is real and large. It is everything your best people are not doing because they are busy being a slow, expensive bridge between two systems that should have been talking to each other all along.
Measure it. The number will make the decision for you.
A few common questions
How much does manual data entry actually cost? A 2025 Parseur–QuestionPro survey put it at around $28,500 per employee per year in the US. The figure varies by role and wage, but the pattern holds everywhere: it is a large, uncounted slice of salary spent on work a machine could do.
What is the error rate for manual data entry? Research consistently puts it around one percent per field. That compounds fast across multi-field records, so a twenty-field order has roughly a one-in-five chance of containing an error.
How do I find the hidden cost in my own team? Track everyone's work in fifteen-minute blocks for two weeks, classify each task as judgment, system, or transfer, and cost the transfer tasks (time × frequency × rate, plus errors). The transfer tasks are where the cost hides.
Isn't this just an argument for cutting staff? No. The biggest return is not the saved wage, it is redirecting skilled people from data-moving onto work that needs judgment. The cost you cut is small next to the value you unlock.